Here are some tips of SQL functions and all scripts passed under SQL Server 2012.
Prerequisite
Let’s assume we have a [Order] table:
create table [dbo].[Order](
Id int identity(1,1)
, purchase_order_no nvarchar(50)
, buyer_user_id nvarchar(50)
, amount_paid float
, order_status nvarchar(50)
, primary key (Id)
)
Then populate with some data.
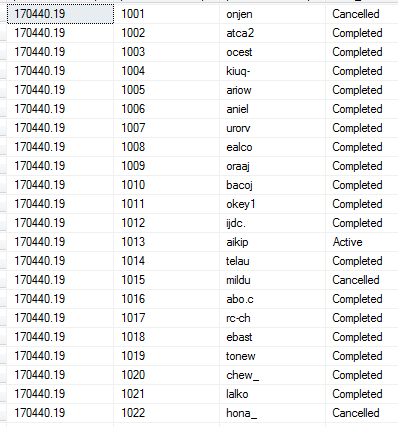
OVER()
OVER allows us to get aggregate information without using GROUP BY. It can by used to retrieve details rows and get aggregate data alongside it.
e.g.
SELECT sum(amount_paid) over()
, purchase_order_no
, buyer_user_id
, order_status
FROM [dbo].[Order]
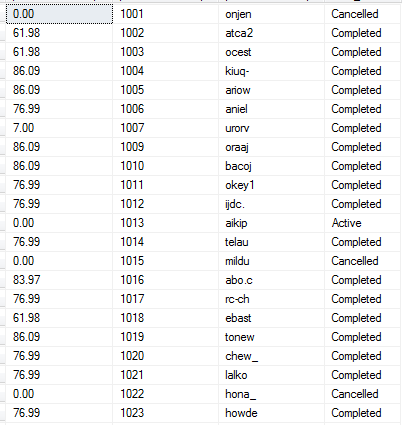
OVER(PARTITION BY)
OVER() is used exposes the entire resultset to the aggregation. However, we can break up the resultset into logical partitions and aggregate data within each partition via PARTITION BY.
e.g.
SELECT sum(amount_paid) over(partition by purchase_order_no)
, purchase_order_no
, buyer_user_id
, order_status
FROM [dbo].[Order]
It is equivalent to
SELECT sum(amount_paid)
, purchase_order_no
, buyer_user_id
, order_status
FROM [dbo].[Order]
group by purchase_order_no, buyer_user_id, order_status
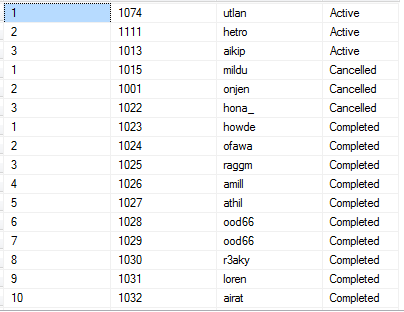
ROW_NUMBER()
ROW_NUMBER() is a ranking function and it generates a run-time column in the resultset which generates sequential number to each row. We often use the ROW_NUMBER function to produce the specific reports. It always together with OVER().
Here is the syntax:
ROW_NUMBER()
OVER (PARTITION BY col1, col2, ....n ORDER BY col1, col2, ....n)
Please note:
- ORDER BY is mandatory. ROW_NUMBER is generated in the resultset based on the column provided in ORDER BY clause
- PARTITION BY is optional which groups the resultset based on the column provided in PARTITION BY clause, the sequence starts with 1.
- The sequence number always starts with 1 within each partition; then, each row was ranked in a sequence under the partition.
e.g.
SELECT ROW_NUMBER() OVER(partition by order_status order by order_status)
, purchase_order_no
, buyer_user_id
, order_status
FROM [dbo].[Order]
RANK()
RANK() behaves like ROW_NUMBER(), except that “equal” rows are ranked the same.
equalsrows means the value of ordered columns ofOVER(ORDER BY column1, column2...)are same.
For a single partition, ROW_NUMBER() numbers all rows sequentially (for example 1, 2, 3, 4, 5). RANK() provides the same numeric value for ties (for example 1, 2, 2, 4, 5).
e.g.
ROW_NUMBER()
SELECT ROW_NUMBER() OVER(order by order_status)
, order_status
FROM [dbo].[Order]
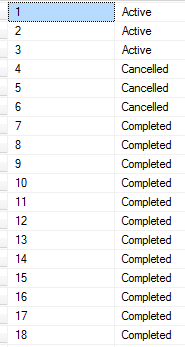
Please note that here we do not specify PARTITION BY inside OVER(). Therefore, it is regarded as a single partition and the sequence number is increased all over the resultset.
RANK()
SELECT RANK() OVER(order by order_status)
, order_status
FROM [dbo].[Order]

Please note that each unique value of row get the same rank. For duplicate values, the same ranking is assigned and a gap appears in the sequence for each duplicate ranking.
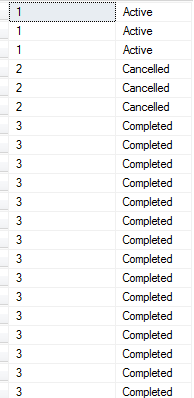
DENSE_RANK()
We can avoid those gaps by using DENSE_RANK()
SELECT DENSE_RANK() OVER(order by order_status)
, order_status
FROM [dbo].[Order]
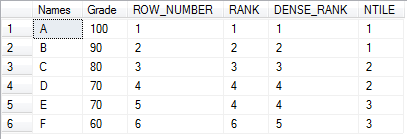
NTILE()
Distributes the rows in an ordered partition into a specified number of groups. The groups are numbered, starting at 1. For each row, NTILE() returns the number of the group to which the row belongs.
e.g.
-- create table
CREATE TABLE dbo.Grades
(
Names VARCHAR(1),
Grade INT
)
GO
-- insert data
INSERT INTO dbo.Grades
VALUES ('A',100),('B',90),('C',80),('D',70),('E',70),('F',60)
GO
Test the data
SELECT Names,
Grade,
ROW_NUMBER () OVER (ORDER BY Grade DESC) as ROW_NUMBER,
RANK () OVER (ORDER BY Grade DESC) as RANK,
DENSE_RANK () OVER (ORDER BY Grade DESC) as DENSE_RANK,
NTILE(3) OVER(ORDER BY Grade desc) AS NTILE
FROM dbo.Grades
Summary
Above ranking functions returns a ranking value for each row either in a partition, or not(a single partition). We can produce the very same result for all functions, but they have different purpose.
PARTITION BY VS. GROUP BY
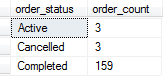
GROUP BY
GROUP BY is used for aggregation and works on the entire query. When a group by clause is used all the columns in the select list should either be in group by or should be in an aggregate function.
e.g.
SELECT order_status, count(*) as order_count
FROM [dbo].[Order]
GROUP BY order_status
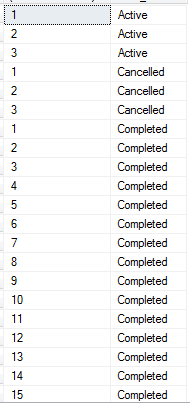
PARTITION_BY
PARTITION BY works like a window function. With it, aggregation or row number functions don’t have the restriction of GROUP BY and they can be calculated alongwith other columns in the select list. Specifically, PARTITION BY can be used to aggregate together with RANK(), or get sequential numbers together with ROW_NUMBER()/RANK().
SELECT ROW_NUMBER() OVER(partition by order_status order by order_status)
, order_status
FROM [dbo].[Order]
OVER(ORDER BY) vs. OVER(PARTITION BY)
When we use window function such as ROW_NUMBER()/RANK()/DENSE_RANK() together with OVER():
ORDER BY is required for OVER(). The reason is, those functions will generate sequential numbers based on a specific order and some additional sequence logic.
PARTITION BY is optional. When we use OVER() without PARTITION BY, the whole resultset is regarded as a single big partition.
e.g.
-
Use
RANK()andPARTITION BY. For each partition, use RANK() to generate sequence number order by three columns,emp_no,a specific id (systId)anda date.SELECT RANK() OVER (PARTITION BY [empNo],[systID],[dtFrom] ORDER BY [empNo],[systID],[dtFrom] ASC) AS Sequence_No, [[empNo],[systID],[dtFrom] FROM ... WHERE [empNo] = '0121663'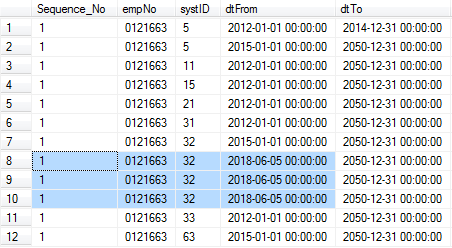
Here, we have two different cases. the resultset was actually partitioned into 10 partitions
row no.1-7: 7 partitions
row no.8-10: 1 partition
row no.11-12: 2 partitions
For each partition, RANK() is used to generate sequential number for different value of orderby columns.
- 9 Partitions (row no.1-7 and 11-12) always rank() from 1 and also only has 1 item for each partition, so they are always 1.
- 1 Partition (row no.8-10) rank() from 1 and all rows have the same value(based on orderby columns), therefore they are also 1.
-
Use
RANK()withoutPARTITION BY. Only useRANK()to generate sequence number order by three columns.SELECT RANK() OVER (ORDER BY [empNo],[systID],[dtFrom] ASC) AS Sequence_No, [[empNo],[systID],[dtFrom] FROM ... WHERE [empNo] = '0121663'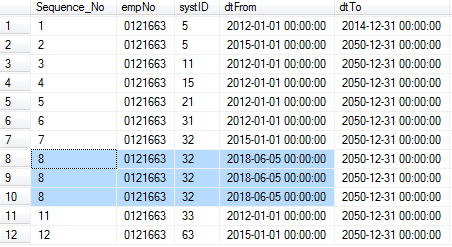
Here, the complete resultset is regared as a single partition. Also, row no. 8-10 have the same value(based on orderby columns). Therefore, they have the same rank() sequestial number and others keep incremental.
-
Use
ROW_NUMBER()andPARTITION BY. For each partition, use RANK() to generate sequence number order by three columns.SELECT ROW_NUMBER() OVER (PARTITION BY [empNo],[systID],[dtFrom] ORDER BY [empNo],[systID],[dtFrom] ASC) AS Sequence_No, [[empNo],[systID],[dtFrom] FROM ... WHERE [empNo] = '0121663'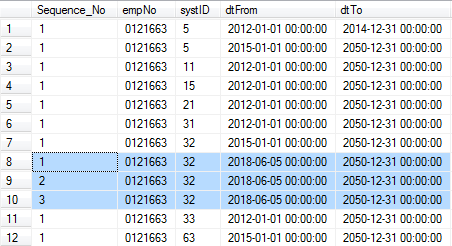
Because of partitioning, the result is divided into 10 partitions.
ROW_NUMBER()simply generates sequential number within each partition and don’t consider “equal” rows.Because row no.8-10 is the same partition,
ROW_NUMBERare generated in a sequence from 1 to 3. Other partitions only contains 1 row separately so always have sameROW_NUMBERbegins from 1. -
Use
ROW_NUMBER()withoutPARTITION BY. Only useROW_NUMBER()to generate sequence number order by three columns.SELECT ROW_NUMBER() OVER (ORDER BY [empNo],[systID],[dtFrom] ASC) AS Sequence_No, [[empNo],[systID],[dtFrom] FROM ... WHERE [empNo] = '0121663'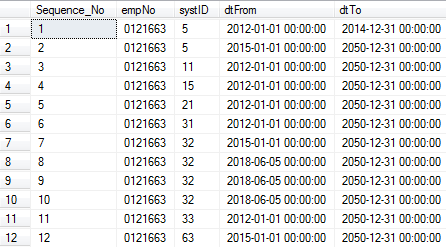
Here, the complete resultset is regared as a single partition. Things will become easier,
ROW_NUMBER()will always generate different sequence number for each row.